A gentle introduction to strings in Go
Working with strings can be a little tricky in Go, especially when we start working with non-English characters. To demonstrate, open up the Go Playground and run the following code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
package main
import "fmt"
func main() {
// this means "hello!" in Chinese
hello := "你好!"
fmt.Printf("hello = %s\n", hello)
// print the length of the string
fmt.Printf("len(hello) = %d\n", len(hello))
// iterate through the string using "for"
fmt.Println("for i := 0; i < len(hello); i++ {")
for i := 0; i < len(hello); i++ {
fmt.Printf("\t%d: %c\n", i, hello[i])
}
fmt.Println("}")
// iterate through the string using "for each"
fmt.Println("for i, c := range hello {")
for i, c := range hello {
fmt.Printf("\t%d: %c\n", i, c)
}
fmt.Println("}")
// contain the string contents in both a []byte and []rune
hello_byte := []byte(hello)
hello_rune := []rune(hello)
// print out the representations
fmt.Printf("[]byte(hello) = %v\n", hello_byte)
fmt.Printf("[]rune(hello) = %v\n", hello_rune)
}
The output might surprise you:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
// say we are working with this string
// which means "hello!" in Chinese
hello = 你好!
len(hello) = 7 // wtf?
// wtf? why doesn't iterating by byte work?
for i := 0; i < len(hello); i++ {
0: ä
1: ½
2:
3: å
4: ¥
5: ½
6: !
}
// seems kinda normal
for i, c := range hello {
0: 你
3: 好
6: !
}
// why are there 7 bytes but 3 runes?
[]byte(hello) = [228 189 160 229 165 189 33]
[]rune(hello) = [20320 22909 33]
Character Encoding
To understand how strings and characters work in Go, we need to have a solid understanding of how character encoding works. Before moving on, read my previous article to learn more about the history of ASCII, Unicode, and UTF-8.
Recall that in UTF-8, Unicode characters can be represented by code points of variable length. Specifically, a UTF-8 code point can take between 1–4 bytes. In the below picture, see how the Chinese character takes up more bytes:
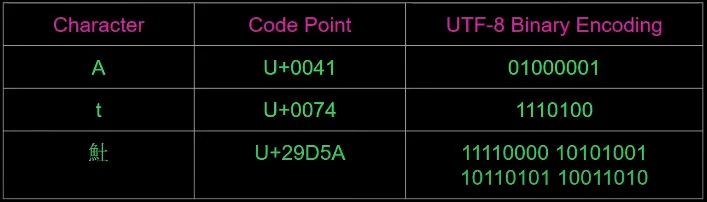
Looking back at the output of the earlier code, we can tell that each of our Chinese characters takes 3 bytes instead of 1. Characters taking multiple bytes explains why our output is so weird!
The string data type in Go
In Go, the string data type is basically the same thing as []byte.
As beginner programmers, we often assume that a string is a bunch of ASCII characters (1 byte). This is a bad assumption, especially when we work with non-English characters.
- A
stringis made up of bytes - A string literal is made up of UTF-8 code points (characters)
- However, one character can be anywhere between 1–4 bytes
- Because of this, we need to convert a
stringinto an array ofrunes - A
runecan hold up to 4 bytes (just likeint32) - When we convert a
stringinto[]rune, eachrunewill hold a character
Recall this output:
1
2
3
4
5
for i, c := range hello {
0: 你
3: 好
6: !
}
The for each loop accounts for UTF-8 code points taking up a variable-length of bytes!
Takeaways
- Consider using for each loops when dealing with strings in Go
- Consider converting strings into []rune with []rune(MY_STRING)
- UTF-8 is backwards compatible with ASCII, which is why the ! showed up properly throughout the output
Recommended Reading
If this article made sense, then consider reading the official Go blog post. Rob Pike goes more in-depth on strings, string literals, bytes, characters, runes, Unicode, and UTF-8.