A gentle introduction to ASCII, Unicode, and UTF-8
A string is made up of characters. But how are characters represented through bits and bytes? This video by LeetCoder takes us through the history of character encoding.
ASCII is a character encoding that:
- Maps bits into characters
- Uses 7 bits for encoding to represent 2^7 = 128 characters
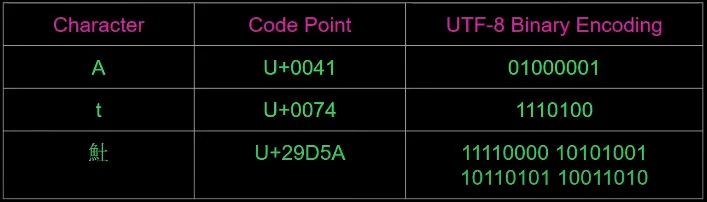
- e.g. 65 = 0b1000001 -> A and 116 = 0b1110100 -> t
The original 7 bits were only enough to represent English characters and punctuation. Since a byte is 8 bits, there was a lot of competition on which other characters should be supported. Enter Unicode.
Unicode is a universal character encoding that:
- Supports many different alphabets and even emojis
- Unlike ASCII, Unicode does not define how its mapping should be implemented
- Only specifies which character refers to which code point
- A code point is a hexadecimal number representing a character
- e.g. 65 = U+0041 -> A
UTF-8 stands for Unicode Transformation Format that:
- Is an algorithmic mapping from every Unicode code point to a unique byte sequence
- Has variable length encoding, allowing code points with small values (like A) to be represented with just one byte
- Can represent characters with up to four bytes
- Is backward compatible with ASCII
- Is the most dominant encoding for the World Wide Web
- In the picture below, notice how ‘A’ and ‘t’ have the same binary encoding in UTF-8 as they do in ASCII
In summary:
- ASCII was the first major encoding, and because of computer limitations it was only 1 byte
- Unicode was invented to address the problem of encoding more languages than just English
- UTF-8 is a variable-length encoding that is backwards compatible with ASCII and is the most popular encoding today
Learn more about character encoding
This post is licensed under CC BY 4.0 by the author.